Audio-Visual Speech Separation with Diffusion based Generative Models
Project Repository : https://github.com/jihoojung0106/SpeechSeparation
1. Introduction
The aim of this research is to isolate the voice of a target speaker from a mixture of voices using visual cues. We utilized cross-attention-based feature fusion mechanism to effectively combine the two modalities for diffusion.
2. Methods
we present the architecture of our audio-visual speech separator network, which leverages the complementary visual cues of both lip motion and cross-modal facial attributes. We use the visual cues in the face track to guide the speech separation for each speaker. The visual stream of our network consists of two parts: a lip motion analysis network and a facial attributes analysis network referencing the VisualVoice and AVDiffuSS. The output of the visual stream network is then fed into diffusion model as condition with audio spectogram. The overall architecture is as follows. 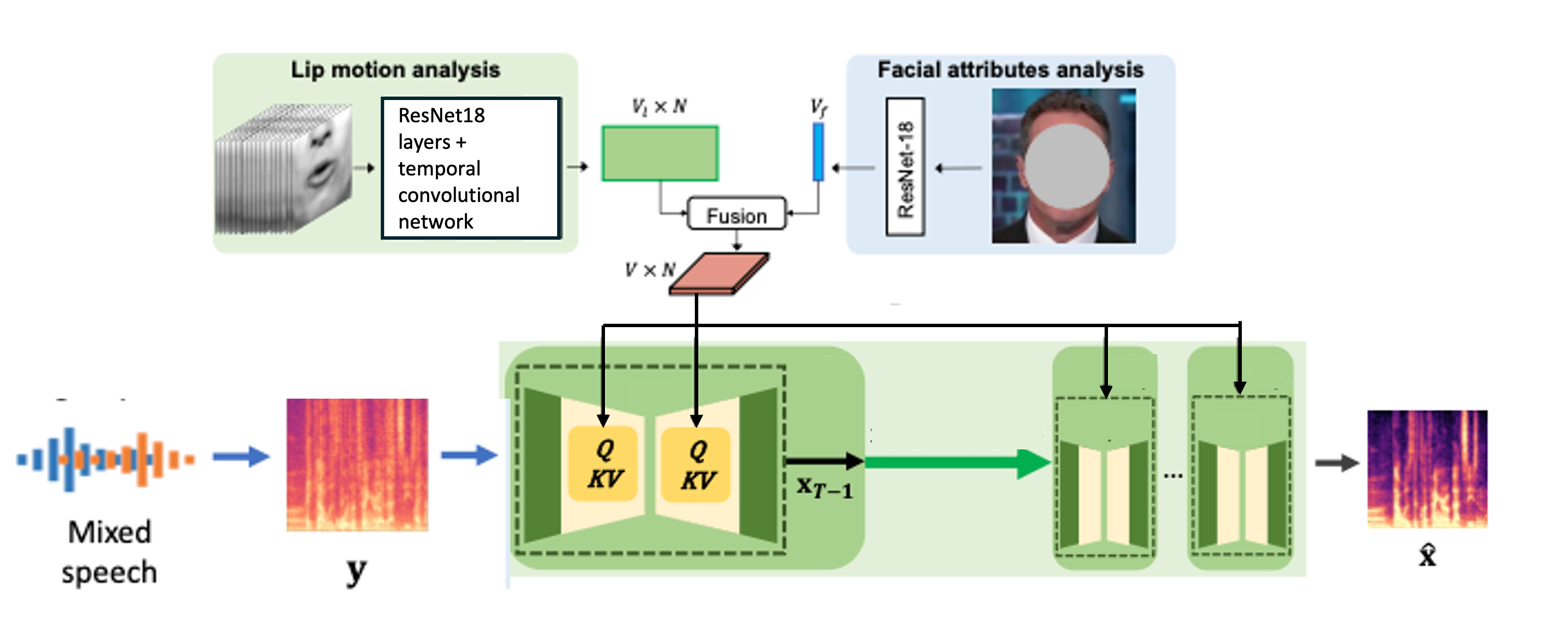
2.1 lip motion analysis network
Following the state-of-the-art in lip reading [46, 44], the lip motion analysis network takes N mouth regions of interest (ROIs)2 as input and goes though the encoder architecture. We adopt the encoder architecture from Talknet, which comprises a series of ResNet18 layers and a temporal convolutional network. After going though the network, to extract the final lip motion feature map of dimension V_l × N.
2.2 facial attributes analysis network
For the facial attributes analysis network, we use a ResNet-18 network that takes a single face image randomly sampled from the face track as input to extract a face embedding i of dimension Vf that encodes the facial attributes of the speaker. We replicate the facial attributes feature along the time dimension to concatenate with the lip motion feature map and obtain a final visual feature of dimension V × N, where V = Vl + Vf.
2.3 Complex Spectrogram
We represent our data in the complex-valued STFT domain, as it has been observed that both real and imaginary parts of clean speech spectrograms exhibit clear structure and are therefore amenable to deep learning models as SGMSE.
2.4 Conditioning by Cross-Attention
We used a feature fusion method using cross-attention as AVDiffuSS. As we adopt the U-net architecture as the backbone of both stages, audio embedding can be represented as e_{a,i} ∈ R^{Ci ×Ti ×Fi}. Here, Ci , Ti , and Fi denote the number of channels, frame lengths, and frequency lengths, respectively, in the i-th U-net layer. By applying frequency-axis pooling to the audio features, we obtain the pooled audio feature denoted as e_{a,i}∈ R^{Ci ×Ti}, which is used as the query, while the visual feature is employed as the key and value. The output of the cross-attention module is repeated Fi times to recover the original shape of the input before averaging across frequencies. Through this process, our model denoises undesired speech while enhancing the voice of the target speaker.
2.5 Audio-Visual Speech Separation with Diffusion
We used the same architecture as SGMSE with additional conditioning of visual features as mentioned in 2.4.
3. Experiments and Results
3.1 Datasets
- VoxCeleb2: This dataset contains over 1 million utterances with the associated face tracks extracted from YouTube videos, with 5,994 identities in the training set and 118 identities in the test set. I used only the test set for the training, because the dataset is too big for my GPU.
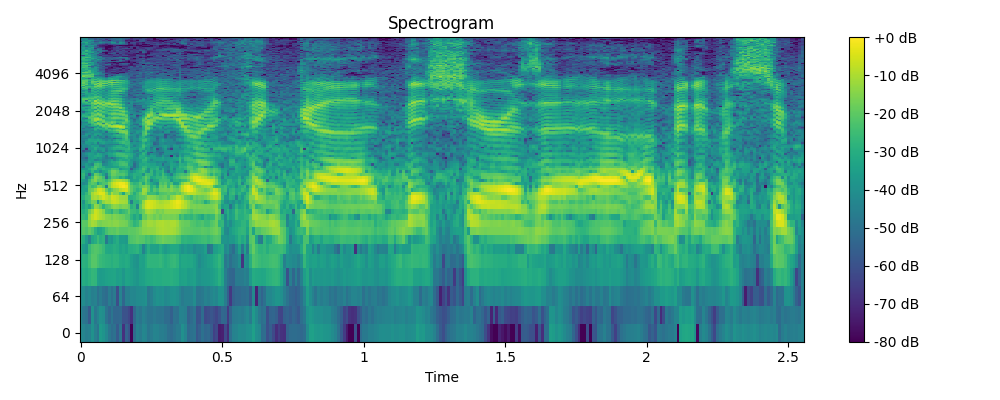
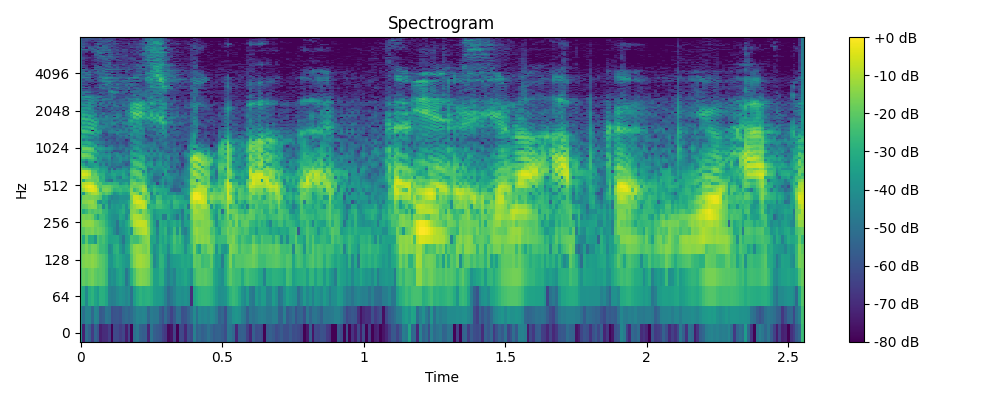
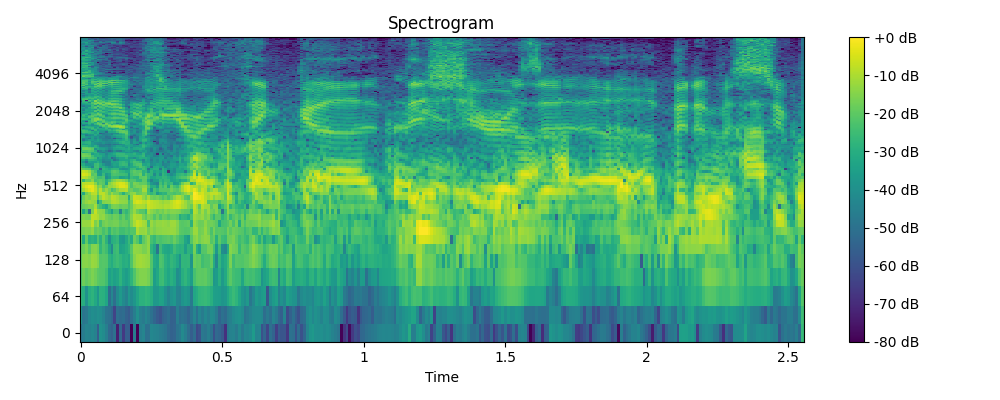
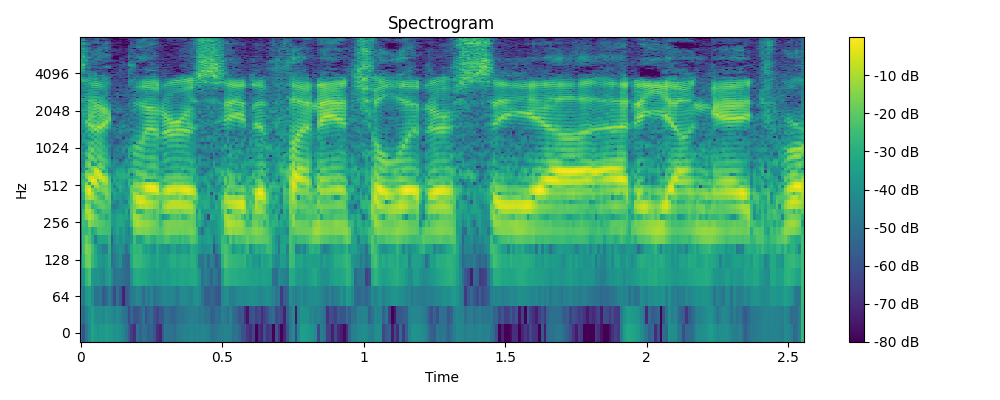
3.2 Demo
- Example 1
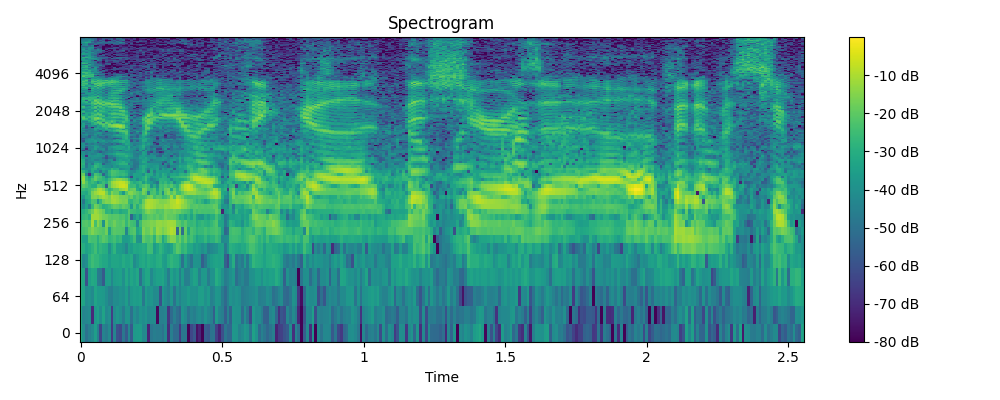
- Example 2
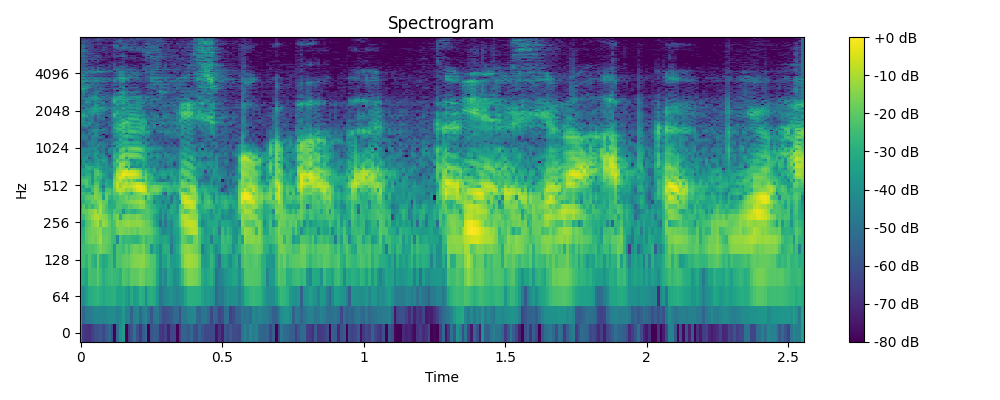
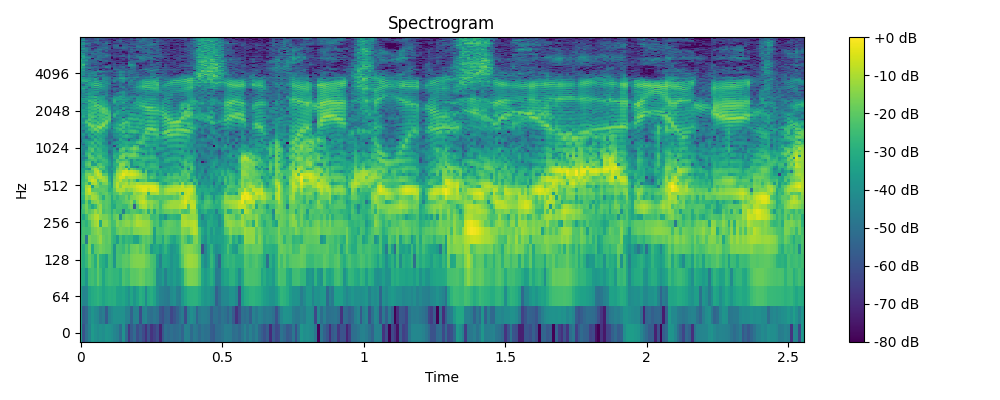
- Example 3
- Example 4