Jihoo Jung
MMAI, KAIST

I am currently a first-year Ph.D. student at MMAI, KAIST, advised by Professor Joon Son Chung. I am interested in understanding and reasoning about the real world through audio, with broader research interests in audio-visual LLMs, agentic systems, and joint audio-visual generative models.
Education
- Korea Advanced Institute of Science and Technology (KAIST), South Korea (Sep. 2026 -)
- Ph.D. in Artificial Intelligence (Advisor: Prof. Joon Son Chung)
- Korea Advanced Institute of Science and Technology (KAIST), South Korea (Aug. 2024 - Aug. 2026)
- M.S. in Electrical Engineering (Advisor: Prof. Joon Son Chung)
- Seoul National University, South Korea (Mar. 2019 - Jul. 2024)
- B.S. in Economics and Computer Science (double major)
- Summa cum laude
selected publications 2 papers | 2 first-authored
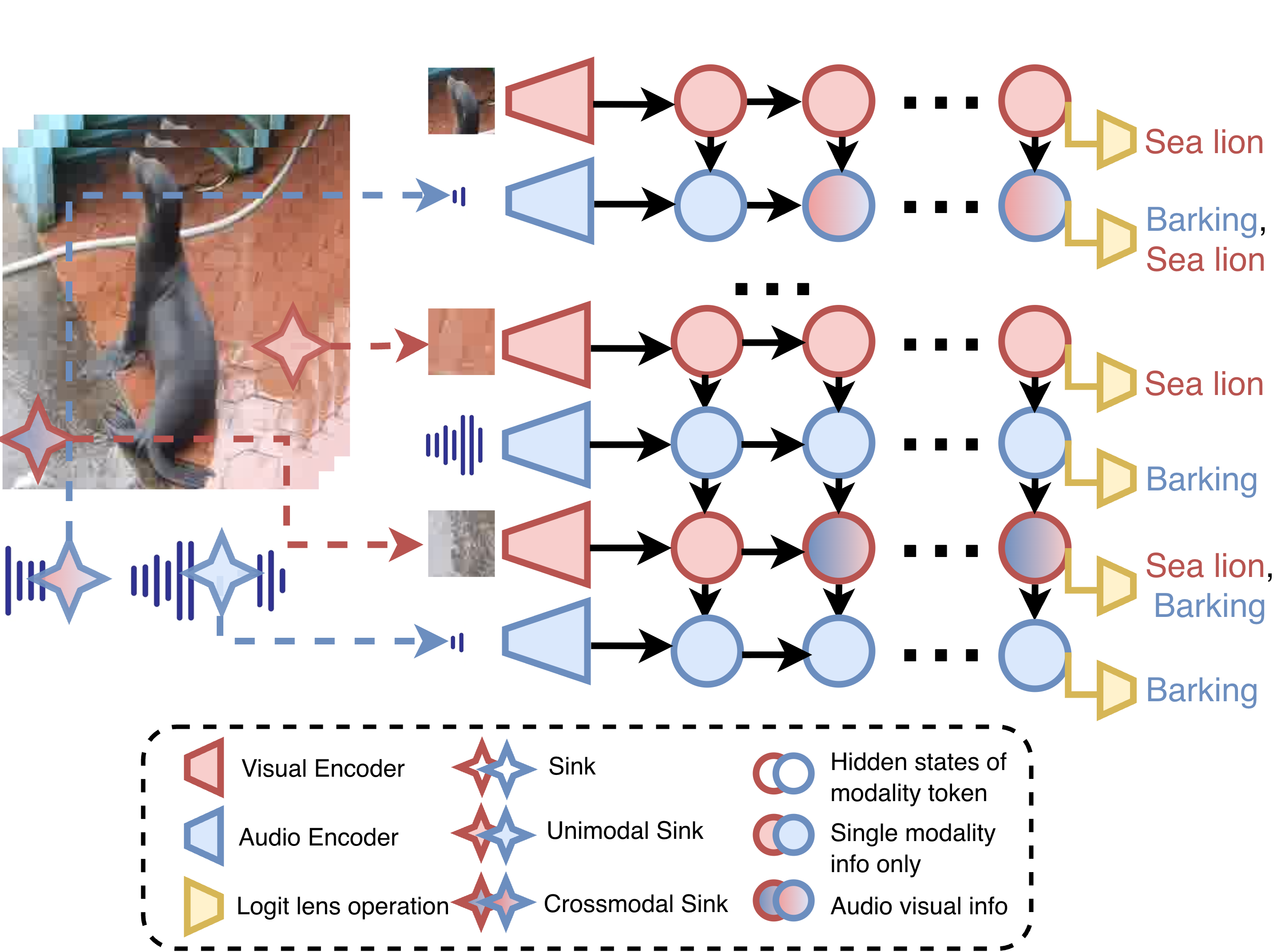
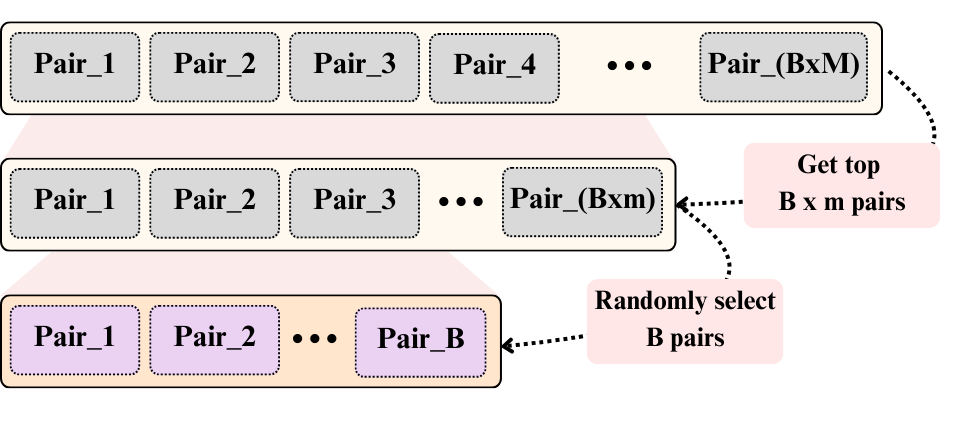
- Probing Cross-modal Information Hubs in Audio-Visual LLMsInternational Conference on Machine Learning (ICML), 2026