Open-SingSong :An Implementation of 'SingSong: Generating Musical Accompaniments from Singing’
Project Repository : https://github.com/jihoojung0106/open-singsong
1. Introduction
The paper titled ‘SingSong: Generating Musical Accompaniments from Singing’ : [https://arxiv.org/abs/2301.12662] by Google Research explores the creation of instrumental music to accompany input vocals using Transformer. Since the code for this paper wasn’t made open-source, we attempted to implement the described methods with a few modifications.
2. Methods
We initially attempted to adhere closely to the methodology outlined in the original SingSong paper. However, due to the substantial size of the model proposed in the original paper, we encountered difficulties in training it effectively with our limited computational resources. As an alternative, we attempted to leverage a pre-trained model for AudioLM, as referenced in the original paper. However, since this model was not publicly accessible, we opted to utilize unofficial pre-trained weights for MusicLM, a closely related model to AudioLM. Subsequently, we adapted our model architecture to accommodate these unofficial pre-trained weights for MusicLM.
We’ll employ two models for the implementation of Singsong:
- Open-musiclm : [https://github.com/zhvng/open-musiclm]: An unofficial implementation of the MusicLM paper, complete with pre-trained weights. We’ll utilize this without any modifications.
- Our semcoarsetosem model: Developed by us, this model predicts instrumental semantic tokens from MERT based on vocal input.
2.1 open-musiclm
open-musiclm is a github repository for pytorch implementation of MusicLM, a SOTA text to music model published by Google with a few modifications with pretrained weights. 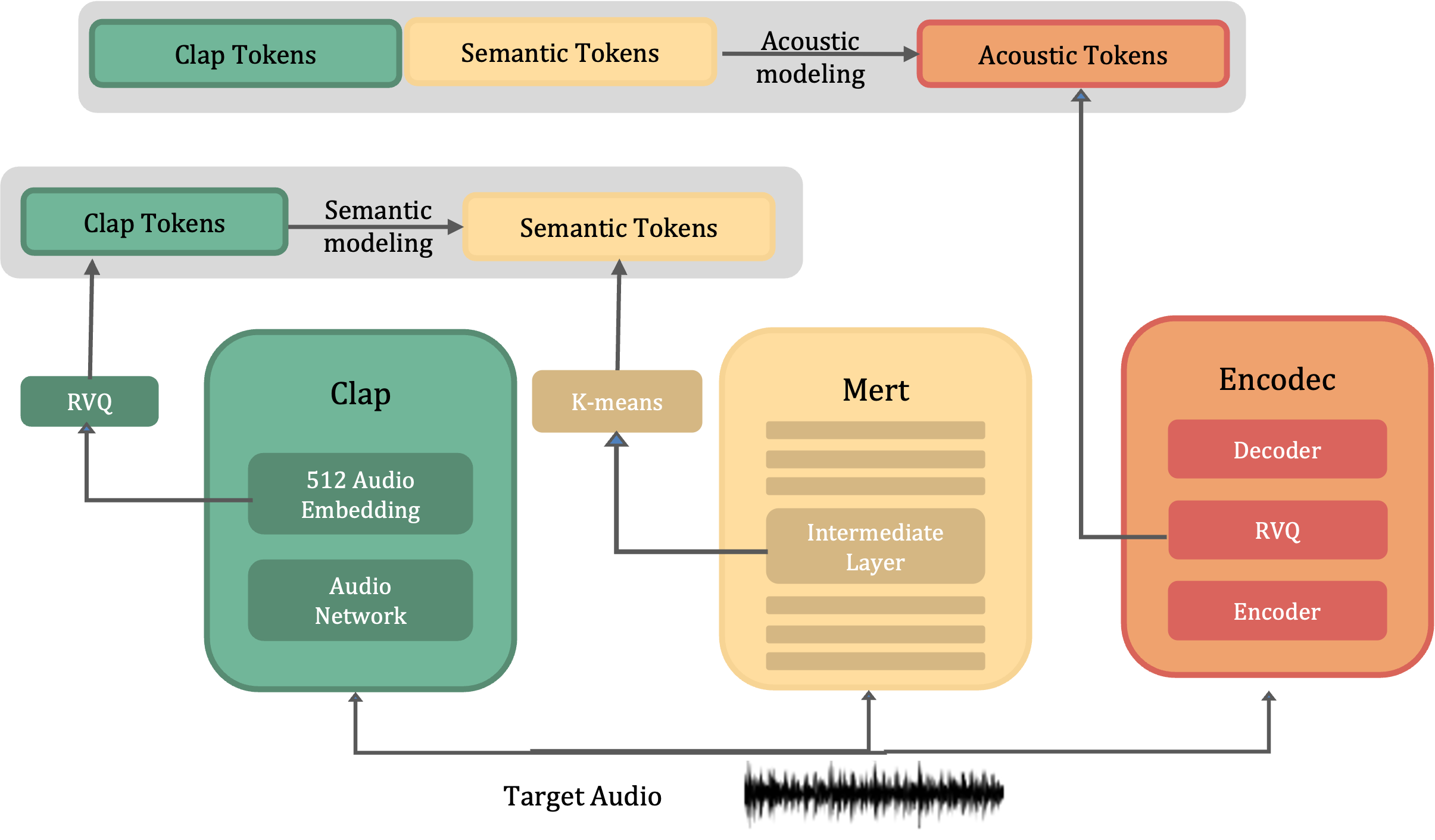
2.2 Our Semcoarsetosem Model
We designed our own semantic model using decoder only transformers. Given vocal input, the model predicts instrumental semantic tokens. Our decoder-only transformer utilizes vocal semantic tokens and coarse acoustic tokens as conditions to predict instrumental semantic tokens. 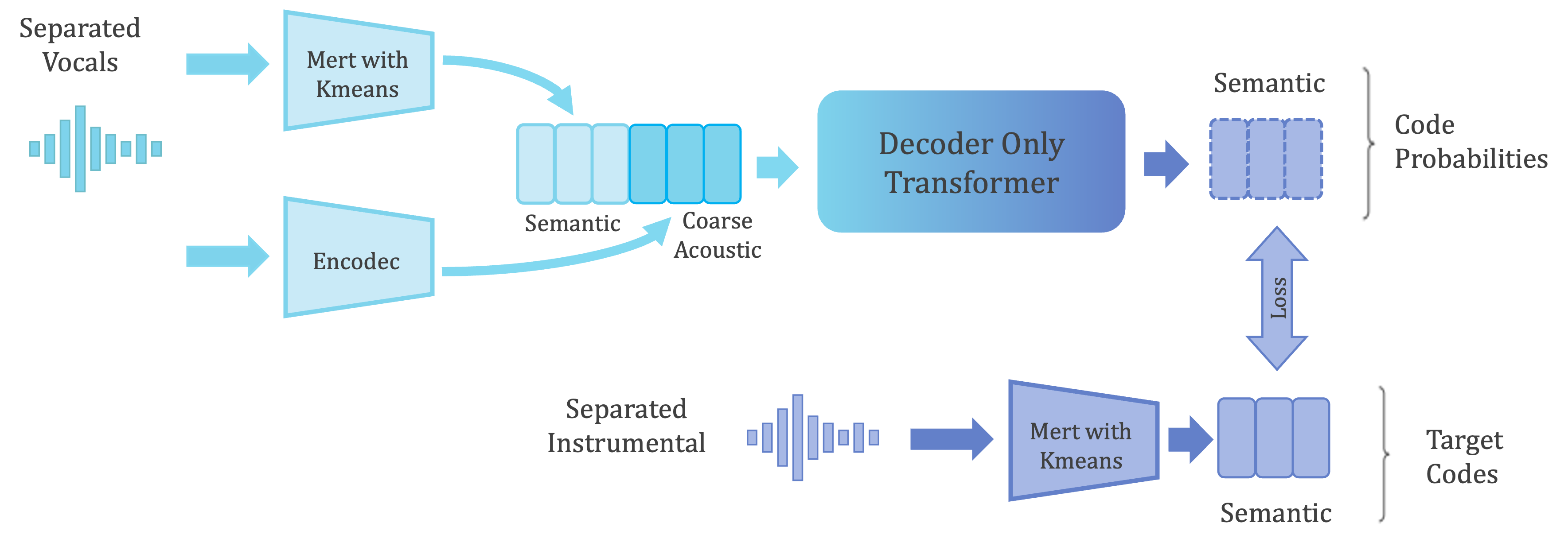
2.3 Inference
During inference, we feed vocals into our semantic model to obtain the predicted instrumental semantic tokens. Simultaneously, we extract clap tokens from the text input, ‘Diverse kinds of instruments and richness.’ These two sets of tokens are concatenated and inputted into the acoustic model of open-musiclm. The resulting acoustic tokens are then decoded using Encodec to produce the final waveforms of the generated instrumental sound. 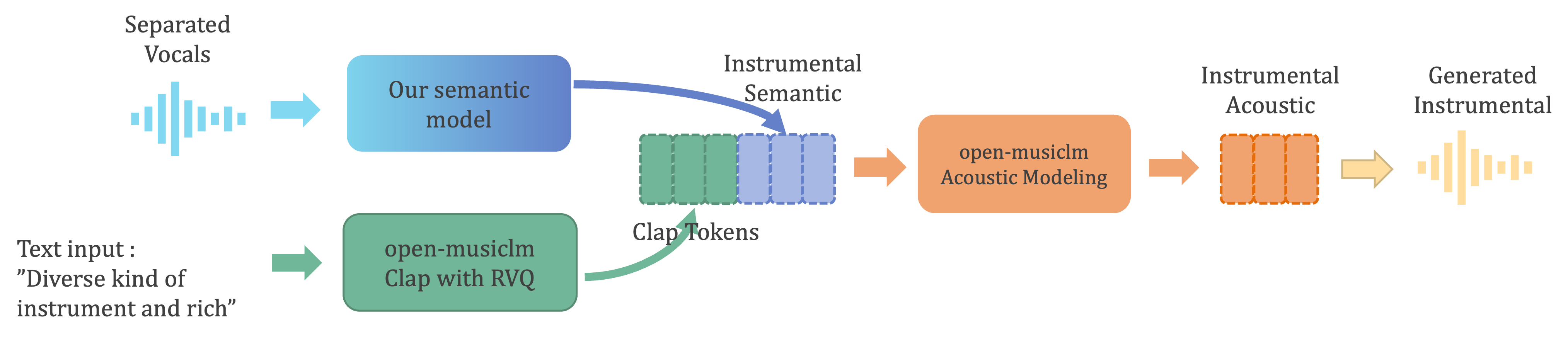
3. Experiments and Results
3.1 Datasets
- MUSDB18 dataset : 10 hours of professional studio- isolated vocal and instrumental from 150 source mixes.
- Filtering data : Non-overlapping 5s clips are extracted from each mix, specifically targeting segments where vocals are discernible. Vocal presence is defined as a peak RMS amplitude exceeding −25dB relative to line level.
- Total clips : 2845 for training, 150 for validation, 1693 for test
3.2 Model Selection and Training Details
- Semantic Tokens
- Model: MERT (MERT-v0 in HuggingFace)
- 7th Embedding Layer quantized with k-means
- Acoustic Tokens
- Model: Encodec (24kHz)
- 3 Coarse quantizers, 5 Fine quantizers
- Our Semcoarsetosem Model Specifications
- 24 layers, 16 attention head Decoder-only Transformer with embedding dimension of 1024
- Training Details:
- Steps: 5k steps
- Batch Size: 2 with 64 gradient accumulations
- Learning Rate: 0.0003 (Learning rate warmup of 6000 steps)
3.3 Demo
Ground Truth(Left) and Open-singsong Generation(Right)
A Classic Education - NightOwl (Train Dataset)
- Actions - South Of The Water (Train Dataset)
- Alexander Ross - Goodbye Bolero (Train Dataset)
- Music Delta - Britpop (Train Dataset)
- Titanium - Haunted Age (Train Dataset)
- Zeno - Signs (Test Dataset)
- Enda Reilly - Cur An Long Ag Seol (Test Dataset)
- Juliet’s Rescue - Heartbeats (Test Dataset)
- Signe Jakobsen - What Have You Done To Me (Test Dataset)
- Triviul feat. The Fiend - Widow (Test Dataset)
4. Discussion and Future Works
4.1 Discussion
The results were quite overfitted to the training dataset. There is an issue with the alignment of the rhythm of vocals and the generated music.
4.2 Possible Reasons for Undesirable Result
The reason why the model doesn’t work properly is that we didn’t predict instrumental coarse features from the input vocals. The original SingSong paper predicts instrumental semantic and coarse tokens from vocal semantic tokens, while we predict only instrumental semantic tokens from vocal semantic and coarse tokens. This decision was made because we aimed to reuse the pretrained weights released by open-musiclm, but might causes alignment of rhythm issue.
4.3 Future works
Include prediction of instrumental coarse features alongside vocals coarse, vocals semantic, and instrumental semantic. Evaluate the model using the FAD score.