Grad-SVS : Korean Singing Voice Synthesis with Diffusion
Project Repository : https://github.com/jihoojung0106/Grad-SVS
1. Introduction
This project performs a Korean singing voice synthesis task using a diffusion model.
2. Methods
We have referenced Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech extensively. Grad-TTS uses a score-based decoder to produce mel-spectrograms of given text. Grad-TTS consists of three modules: encoder, duration predictor, and decoder. For more details, please refer to the figure below and the original paper. 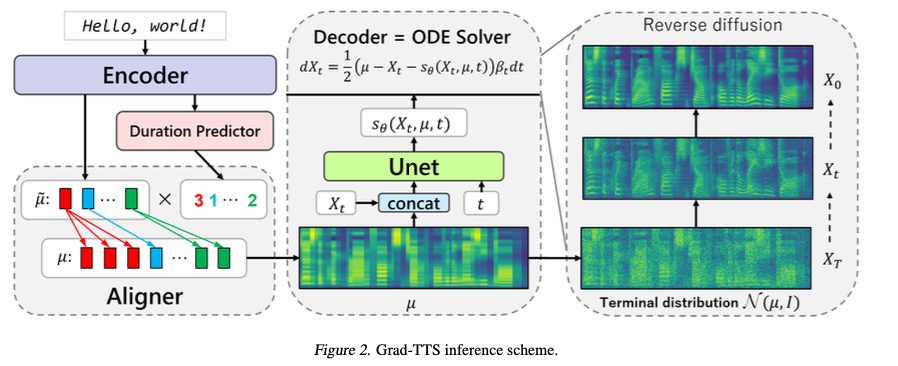 In TTS, a duration predictor is required to convert the encoded text sequence into frame-wise features of the spectrogram. However, in singing voice synthesis, the duration of each syllable is predetermined, so a duration predictor is not needed. Therefore, the duration predictor is removed from the Grad-TTS model architecture. Instead, since pitch information is included as input, we define a text encoder and a pitch encoder to encode the input information.
In TTS, a duration predictor is required to convert the encoded text sequence into frame-wise features of the spectrogram. However, in singing voice synthesis, the duration of each syllable is predetermined, so a duration predictor is not needed. Therefore, the duration predictor is removed from the Grad-TTS model architecture. Instead, since pitch information is included as input, we define a text encoder and a pitch encoder to encode the input information. 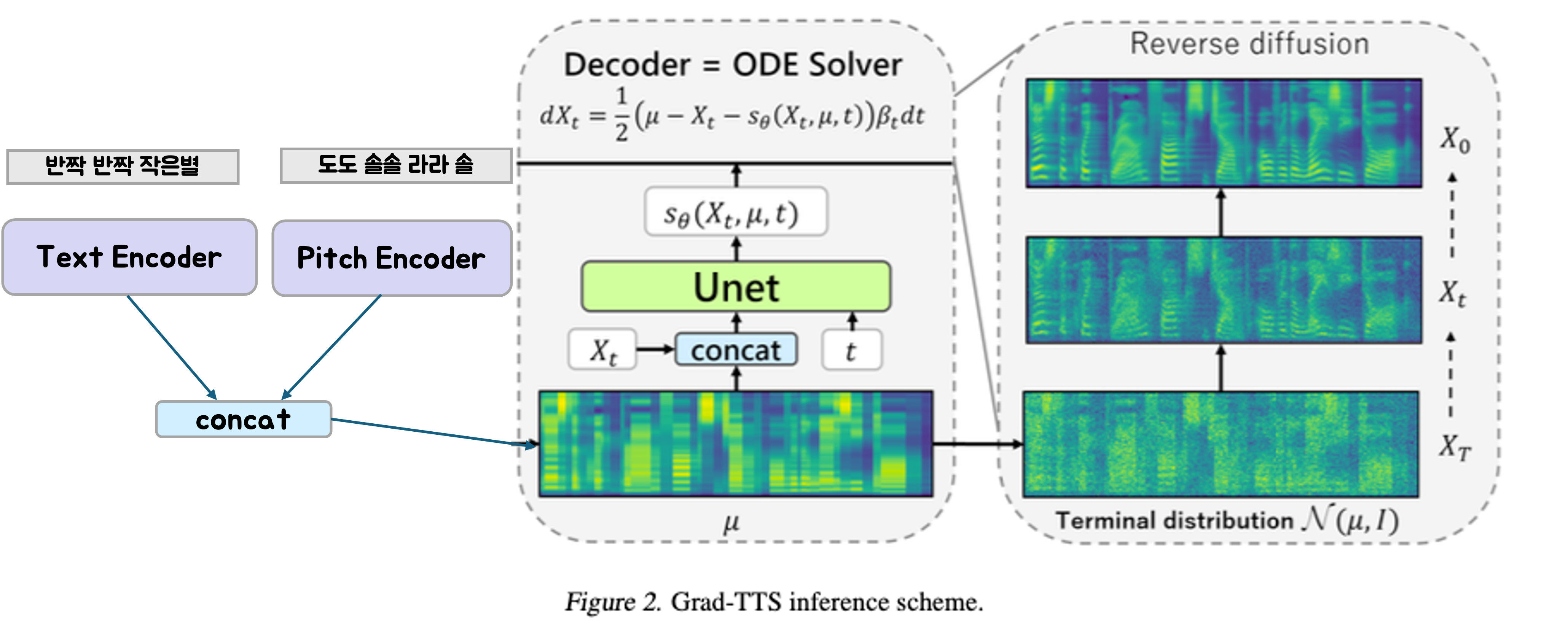 Unlike Grad-TTS, which defines duration loss, prior loss, and diffusion loss, this project uses only prior loss and diffusion loss.
Unlike Grad-TTS, which defines duration loss, prior loss, and diffusion loss, this project uses only prior loss and diffusion loss.
3. Experiments and Results
3.1 Datasets
- We used the Children’s Song Dataset (CSD), an open dataset composed of English and Korean children songs sung by a professional female singer. Each song is sung twice in two different keys. We used 50 Korean songs, which totals approximately two hours in length excluding silence intervals. Each song is accompanied by MIDI and text annotations. We used a rule-based Korean grapheme-to-phoneme method to preprocess raw text. Data preprocessing follows the methodology from the paper ‘MLP SINGER: Towards Rapid Parallel Korean Singing Voice Synthesis’. For detailed methods, please refer to the code provided in the paper.
3.2 Demo
- Ground Truth(Left) and Grad-SVS Generation(Right)
- 당신은 누구십니까
- 창밖을 보라